
Word embeddings are vector representations of words, which can then be used to train models for machine learning.
One method to represent words in vector form is to use one-hot encoding to map each word to a one-hot vector. However, one-hot encoding of words do not measure relationships between words, and result in huge sparse matrix representations which consume memory and space. n-grams can be used to capture relationships between words, but do not resolve the size of the input feature space, which grows exponentially with the number of n-grams. Using n-grams can also leads to increasing data sparsity, which means more data is needed in order to successfully train statistical models.
Word2vec embeddings remedy to these two problems. They represent words in a continuous N-dimensional vector space (where N refers to the dimensions of the vector) such that words that share common contexts and semantics are located in close proximity to one another in the space. For instance, the words "doctor", "physician" and "radiologist" share similar contexts and meanings and therefore share a similar vector representation. Word2Vec trains a neural network with a single hidden layer with the objective of maximizing the probability of the next words given the previous words.
The network is not used for the task it has been trained on. The rows of the hidden layer weight matrix are used instead as the word embeddings. For a hidden layer with N=300 neurons, the weight matrix W size is V x N, where V is the size of the vocabulary set. Each row in W corresponds to the embedding of a word in the vocabulary and has size N=300, resulting in a much smaller and less sparse vector representation then 1-hot encondings (where the dimension of the embedding is o the same order as the vocabulary size).
This tutorial explains
- how to use a pretrained word2vec model with Gensim and with Spacy, two Python libraires for NLP,
- how to train your own word2vec model with Gensim,
- and how to use your customized word2vec model with Spacy.
Spacy is a natural language processing library for Python designed to have fast performance, and with word embedding models built in. Gensim is a topic modelling library for Python that provides modules for training Word2Vec and other word embedding algorithms, and allows using pre-trained models.
This tutorial works with Python3. First make sure you have the libraries Gensim and Spacy. You can install them with pip3 via pip3 install spacy gensim in your terminal.
Word Vectors With Spacy
Spacy provides a number of pretrained models in different lanuguages with different sizes. I choose to work with the model trained on written text (blogs, news, comments) in English. A list of these models can be found here: https://spacy.io/models.

The similarity to other words, the vector of each processed token, the mean vector for the entire sentence are all useful attributes that can be used for NLP. Predicting similarity is useful for building recommendation systems or flagging duplicates for instance.

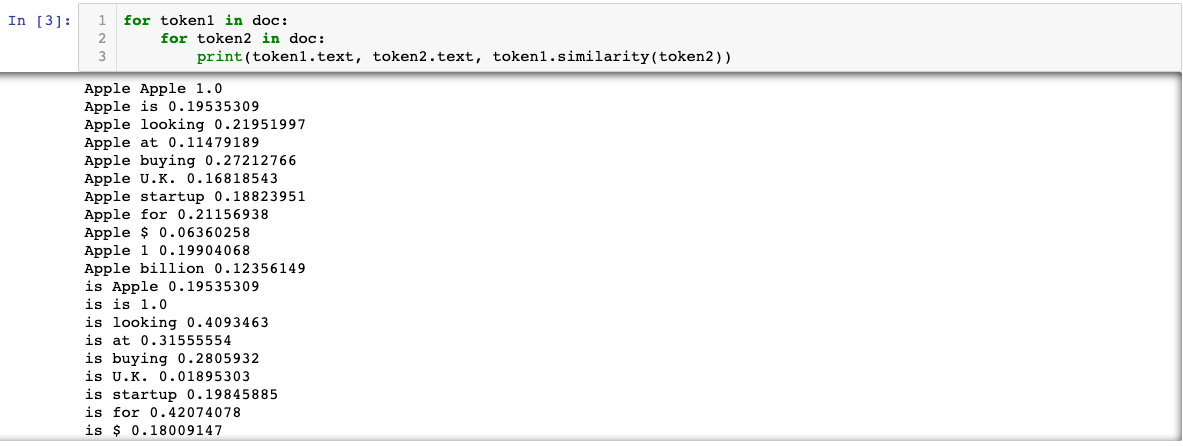
In the example below, the words software, computer and mail are all present in the vocabulary the model was trained on, and their vectors can be accessed. The token hjhdgs is out-of-vocabulary and its vector representation consists of a zero vector with dimension of 300.

Word Vectors With Gensim
Gensim does not provide pretrained models for word2vec embeddings. There are models available online which you can use with Gensim. One option is to use the Google News dataset model which provides pre-trained vectors trained on part of Google News dataset (about 100 billion words). The model contains 300-dimensional vectors for 3 million words and phrases. The archive is available here: GoogleNews-vectors-negative300.bin.gz from https://code.google.com/archive/p/word2vec/.


![]()

The raw output vectors can be accessed via gensim_model['computer'], and can be used for your NLP task.
Creating your own word2vec model with Gensim
A pretrained word embeddings model might not capture the specificities of the language for a spcefic domain. For instance, a model trained with Wikipedia articles might not have exposure to words and other aspects to domains such as medicine, or law. Out of vocabulary words might be another issue with a pretrained model. Training your own word2Vec might lead more optimal solutions for your application.
It is possible to train your own word2vec model with Gensim. This section covers the necessary steps. To test the impact of having a customized word2vec model, I downloaded the 2017-10-30 Sample dataset (10k papers, 10MB) from Open Corpus https://api.semanticscholar.org/corpus/download/, which includes abstracts from 10k published research papers in Neuroscience, and Biomedical fields. I expect the customized model will provide word vectors that are more accurate for words in the neuroscience, and biomedical fields than the Google News dataset pretrained model.
We limit the training to 10k research papers for demonstration purposes. However, a larger dataset might be better suitable for a real application.
Input For Training
Gensim’s word2vec expects a sequence of sentences as its input. Each sentence is a list of words. Sentences can be a generator, reading input data from disk on-the-fly, without loading the entire corpus into RAM. Instead of keeping a an in-memory list of sentences, which can use up a lot of RAM when the input is large, we build the class IterableSentences, where each file in the corpus is processed line by line.
We use regex to preprocess the text. Every sentence is convereted to lowercase and all the digits, special characters, and extra spaces from the text are removed. After preprocessing, the generator returns a list of lowercase words.
Additional preprocessing can be added in IterableSentences.__iter__.

IterableSentences looks at text files within a folder. In my case, all the abstracts are loaded in one text file in a directory called dataset.
![]()
Training
Word2vec accepts several parameters that affect both training speed and quality. We focus here on few:
- min_count to ignore words that do not appear above a certain level and for which there isn't enough data to learn useful representations.
- size to set the size opf the hidden layer. A larger number of neurons in the hidden layer means a larger vector reprenstation, which can lead to more accurate models. However, larger numbers require more data for training.
The other paramters to control training can be found here.

Exploring the Customised Model
To explore the benefits of having a customized model, we look at some specific examples:
In the example below, the customized model exclude brain from the list ['woman', 'ovarian', 'brain'] which is more accurate than excluding woman when looking at a biomedical domain.


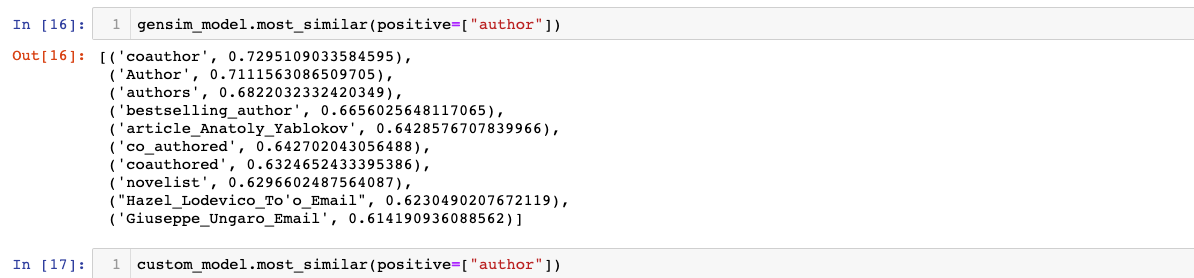
When looking at the most similar word to author, the customised model provides a list that is more specific to research papers, whereas the pretrained model provides a list that is more specific to literary books.

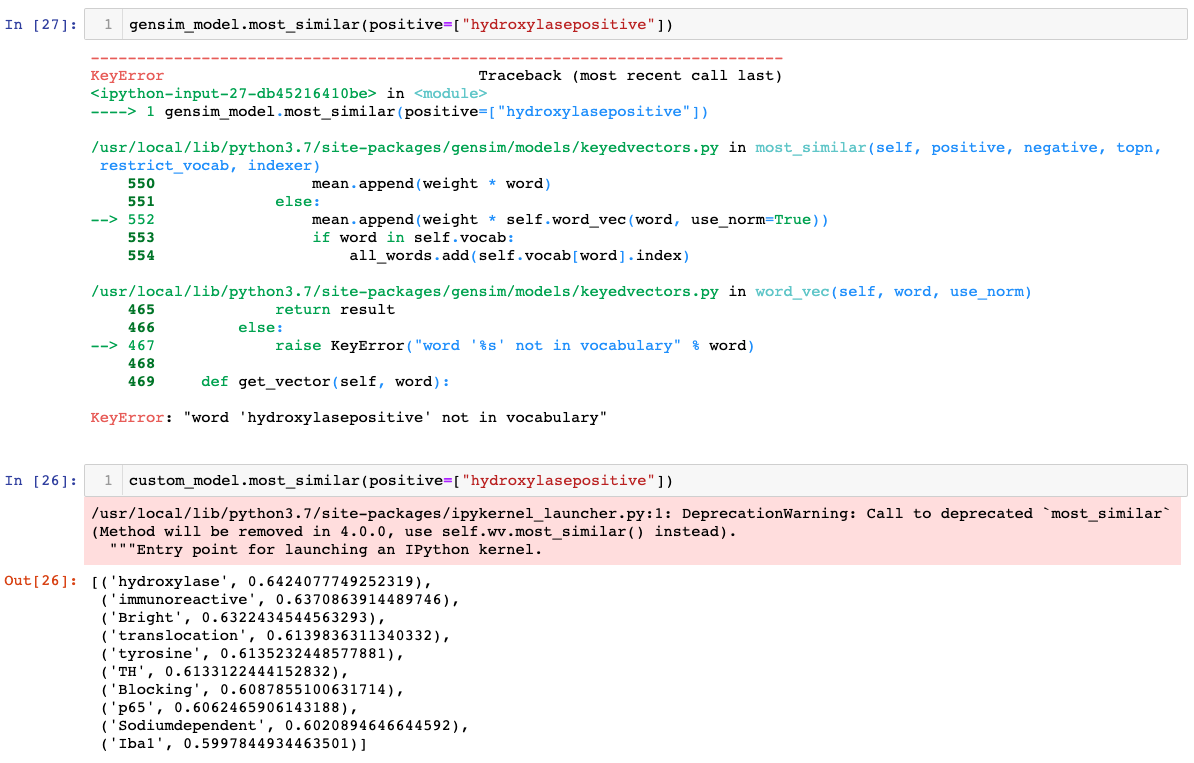
For the word hydroxylasepositive, the pretrained model fails since the word is OOV, which is not the case for the customised model.
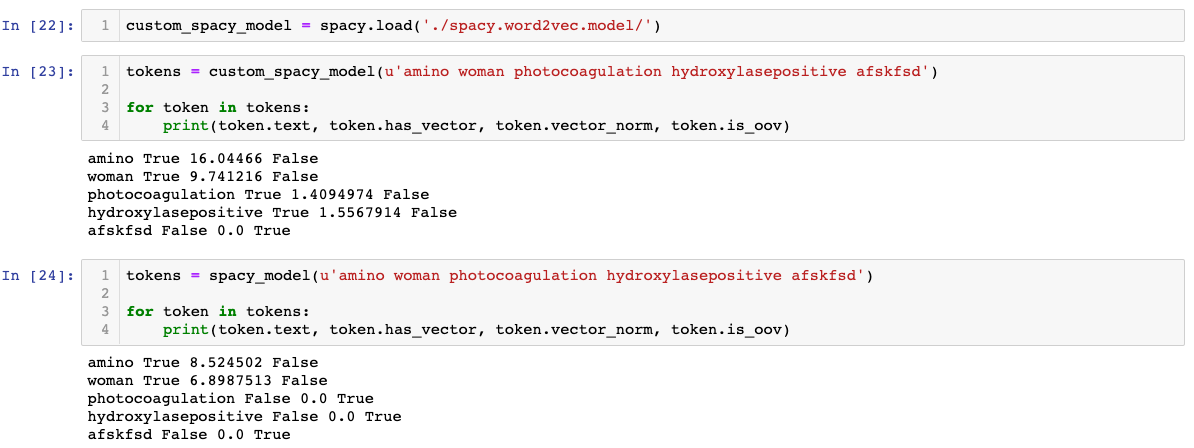
Using The Customised Model With Spacy
It is possible to use the model we trained with Spacy, taking advantage of the tools that Sapcy provides.
Here is a summary of the steps to use the customized model with Spacy:
Save your model in plain-text format:
![]()
Gzip the text file:
![]()
which produces a word2vec.txt.gz file.
Run the following command:

Load the vectors in Spacy using:
The word2vec model accuracy can be improved by using different parameters for training, different corpus sizes or a different model architecture. Increasing the window size of the context, the vector dimensions, and the training datasets can improve the accuracy of the word2vec model, however at the cost of increasing computational complexity.
Training speed and performance can be improved by removing very frequent words that provide little information, such as a, the and and.
Frequently occurring bigrams and trigrams can be detected with Gensim Phraser, which can improve the accuracy and usefulness of the embeddings. For example, the model can be trained to produce a vector for new_york, instead of training vectors for new and york.
References
- Word2vec Tutorial, Radim Řehůřek, https://rare-technologies.com/word2vec-tutorial/
- In spacy, how to use your own word2vec model created in gensim? https://stackoverflow.com/questions/50466643/in-spacy-how-to-use-your-own-word2vec-model-created-in-gensim
- Word Vectors and Semantic Similarity, https://spacy.io/usage/vectors-similarity
- models.word2vec – Word2vec embeddings, https://radimrehurek.com/gensim/models/word2vec.html
More Tutorials to Practice your Skills on:
– Introduction to Missing Data Imputation
– Hyperparameter tuning in XGBoost
– Introduction to CoordConv Architecture: Deep Learning
– Neural Networks in Python
– Getting started with XGBoost

By Chris Tegho
Chris is currently working as a Machine Learning Engineer for a startup, Calipsa. His interests include Bayesian neural networks, reinforcement learning, meta reinforcement learning, variational inference and computer vision. He completed his Masters in machine learning at the University of Cambridge, in August 2017. For his thesis, he worked on improving uncertainty estimates in deep reinforcement learning, through Bayes By Backprop, for the application of dialogue systems.
In the past, he's worked as a cloud developer and consultant for an ERP consulting company in Montreal, and did my Bachelors in Electrical Engineering at McGill.