We enable organisations, teams and individuals to achieve success in digital revolution
Centres of Excellence
We believe in working in partnership with our clients to develop expert programmes that meet their needs and deliver impact for our learners. Our Centres of Excellence provide the customer focus and technical expertise to ensure that the transformative power of our programmes sets us apart.
Digital Transformation
Develop professionals that can lead and manage the transformation to adopt new technologies like AI.
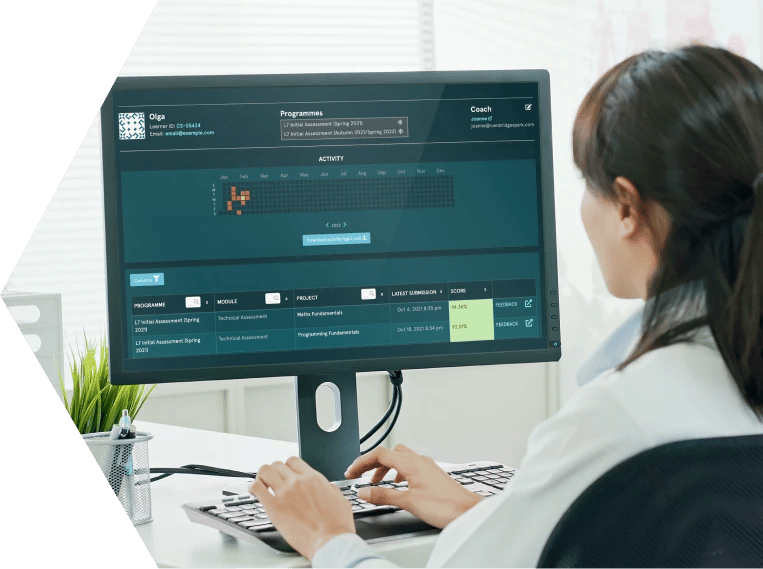
We deliver digital skills programmes that make an impact: our data apprentices have recorded over £300 million in business value from applying their new skills. Our success is driven by our blended learning approach, which delivers virtual instructor-led training supported by self-paced e-learning, and our unique learner support model which includes EDUKATE.AI, our innovative online learning platform. EDUKATE.AI simulates a real industry environment for learners to practice their skills, with automatic feedback on their assignments enhancing the learning journey - so far EDUKATE.AI has provided over 550,000 pieces of automated feedback, helping accelerate the speed to impact.
EDUKATE.AI
tailored learning platform
Technical Experts
in AI education and digital skills
Blended Learning
for all our programmes
Focussed on ROI
with industry simulated projects
A real-world learning experience
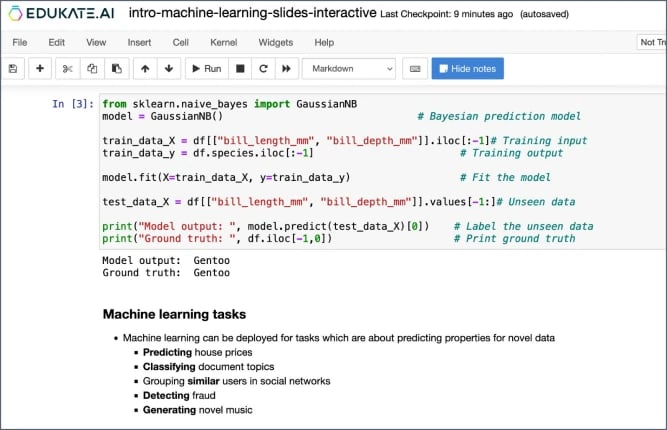
EDUKATE.AI is our learning experience platform which delivers a seamless experience in one place and accelerates learning and impact through real practice on real projects with immediate, personalised feedback on code.
The Group Head of Business Intelligence at Exertis speaks about his and his team's experience upskilling with Cambridge Spark's data analyst apprenticeship programme.
Whether you or your team are just starting to leverage data and need to build basic data skills, or you're an experienced data scientist and want to excel with advanced machine learning, Cambridge Spark have a data programme fit for you.























.png)














.svg)
%20(2).png)
%20(2).png)




.png)

.svg)